1. どんなもの?
画像からスタイルを適用したキャプションをUnpaired imagesから生成する研究. Term Generatorを用いて画像に関連する単語を生成して,生成された単語列からLanguage Generatornを用いてスタイルを適用したキャプションを生成する.
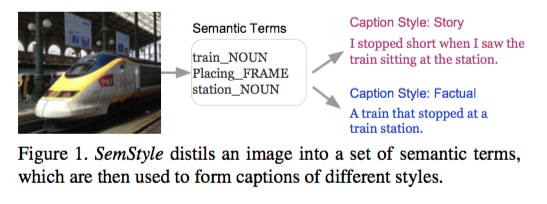
2. 先行研究と比べてどこがすごいの?
画像とキャプションのPaired dataを用いず,キャプションデータのみを用いてスタイルを適用したキャプションを画像から生成する手法を提案.
3. 技術や手法の"キモ"はどこにある?
Term Generator と Language Generatorの階層的構造によってスタイルを適用したキャプションを生成. Term Generatorの学習時のみ画像とキャプションから構成されるPaired Dataを用いる. Language Generatorの学習には,スタイルが適用されたキャプションのみを用いる.
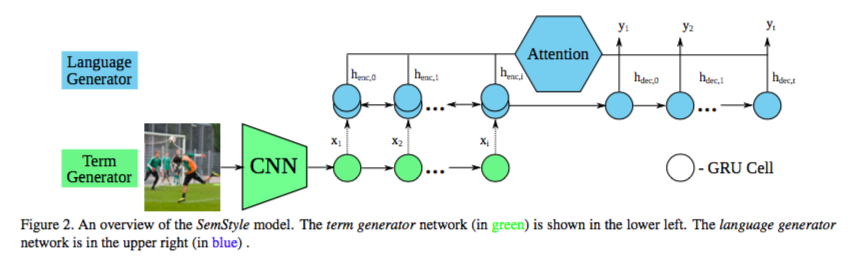
Term Generator
意味論的に重要であると考えられる単語の羅列を画像から生成する. 単語列の生成には,Inception-v3とGRUによるEncoder-Decoder構造を取っている. これは元祖Image caption generatorであるShow and tellと同様のネットワーク構造である.
また,教師データにはキャプションから前置詞や助詞などの機能語を取り除いたものを用いる lemmatizationやPOSなどの処理も施す. 動詞は画像キャプション生成に重要なワードだが,スタイルを持つためそのまま利用せず、FrameNetを用いて上位概念の単語に置換する.
Language Generator
Term Generatorにより生成された単語の羅列からスタイルを適用したキャプションを生成する. Bi-directionalのGRUにAttentionを適用したEncoder-Decoder構造を取っている.
教師データには単語の羅列と対応するキャプションが必要であるため,上述の手法によりキャプションから単語の羅列へのマッピングを作成する.
しかしStyled textを用いて作成された単語の羅列のみを用いてLanguage Generatorを学習させた場合,Paired dataから学習されたTerm Generatorによって出力される単語羅列を分布が異なってしまう(Paired dataの単語羅列がStyledtextの単語羅列に十分に現れるとは想定されないため)
そこでPaired data内におけるdescriptive CaptionとStyled textの両方を用いてLanguage Generatorを学習させる.
指定したスタイルのキャプション(Descriptive or Styled)を生成するため,入力される単語羅列の先頭に
Paired Dataによって学習されたTerm Generatorと組み合わせることによって,様々なスタイルのキャプションを生成することが可能になる,
4. どうやって有効だと検証した?
データセット
- MSCOCO
- bookcorpusに含まれる恋愛小説
比較対象
Descriptive Caption
- CNN+RNN+coco(Show and tellのモデル)
- StyleNet(Factored LSTMを用いてDescriptive Captionを生成)
- SemStyle-cocoonly(提案手法でLanguage Generator部分をDescriptive captionのみで学習)
- SemStyle-coco(提案手法で単語羅列の先頭に
を付与したもの)
Styled caption
- StyleNet(Factored LSTMを用いてStyled Captionを生成)
- TermRetrieval(Term Generatorによって生成された単語羅列を用いてStyled textのコーパスから文章を引っ張ってきたもの)
- neural-storyteller
- JointEmbedding
- SemStyle(提案手法)
- SemStyle-unordered(提案手法でTerm Generatorによって生成される単語羅列のランダムにしたもの)
- SemStyle-words(提案手法でTerm Generatorによって生成される単語羅列にlemmatizationやPos, FrameNetなどを適用しない)
- SemStyle-lempos(提案手法でTerm Generatorによって生成される単語羅列にFrameNetを適用しない)
- SemStyle-romanly(提案手法でTerm Generatorをbookcorpusの恋愛小説のみで学習)
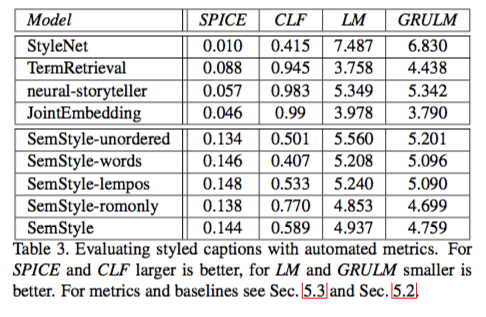
評価
- BLEU, METEOR, CIEDErは高いほど良い,
- SPICE, CLF, LM, GRULMは小さいほど良い.

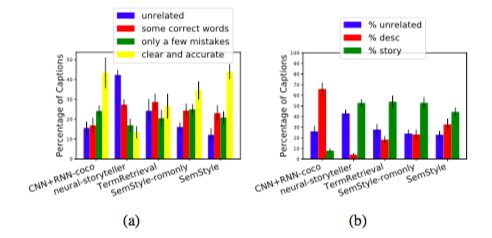
human evaluation
- (a) 生成されたキャプションがどれほど画像の状況を言い表しているか.
- (b) 生成されたキャプションがUnrelated, Descriptive, Styledのどれに属するか.
5. 議論はあるか?
- (a), (b),(c), (d)は正しく生成されたキャプション.
- (e), (f)は生成に失敗したキャプション

生成に成功したキャプションでは,Storyの方がDescriptiveより印象深い単語を使用していることが読み取れる. また,過去形や定冠詞の使用,一人称視点からの叙述が見られる.
失敗例は文法的には正しいが,常識に反するものが多く見られる.
6. 次に読むべき論文はあるか?
- 'Melvin Johnson, Mike Schuster, Quoc V. Le, Maxim Krikun,Yonghui Wu, Zhifeng Chen, Nikhil Thorat, Fernanda Viégas,Martin Wattenberg, Greg Corrado, Macduff Hughes, Jeffrey Dean', "Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation",'EMNLP 2017'
- 'Chuang Gan, Zhe Gan, Xiaodong He,Jianfeng Gao,Li Deng', 'StyleNet: Generating Attractive Visual Captions with Styles', 'CVPR 2017'
論文情報・リンク
Articles connexes
- Thu 26 July 2018
- Rich Image Captioning in the Wild
- Mon 23 July 2018
- Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
- Mon 11 June 2018
- Show, Attend and Tell: Neural Image Caption Generation with Visual Attention