1. どんなもの?
物体検出によるbottom-up attentionと重み付き平均を用いたtop-down attentionの両方を組み合わせることにより,Image CaptioningとVisual Question Answeringの両方のタスクにおいてSOTAを達成.

2. 先行研究と比べてどこがすごいの?
従来のImage captioningやVideo Question Answeringのタスクではほとんどの場合,逐次生成されるキャプションの結果や質問と画像のpixel wise feature vectorによる重み付き平均によるtop-down型のvisual attentionを用いる. 一方で本研究では,画像のpixel wise feature vectoreではなく,Faster R-CNNなどの物体検出アルゴリズムを用いたbottom-up attentionの出力結果に対してtop-down attentionを適用している.
3. 技術や手法の"キモ"はどこにある?
bottom-up attentionの出力結果をtop-down attentionに適用している. 物体検出アルゴリズムとして知られるFaster R-CNNの出力結果である部分画像に対してmean-pooled convolutionを適用したfeature vectoresに対してattentionを貼る. さらに,これらfeature vectoresの平均を取ったのをNetworkの入力として用いる.

bottom-up attentionを用いる以外はImage Captioning及びVisual Question AnsweringのNetworksに変わった構造は見られない.
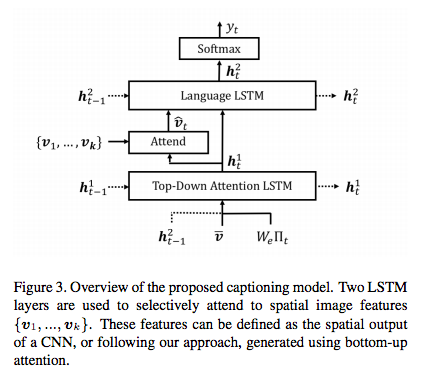
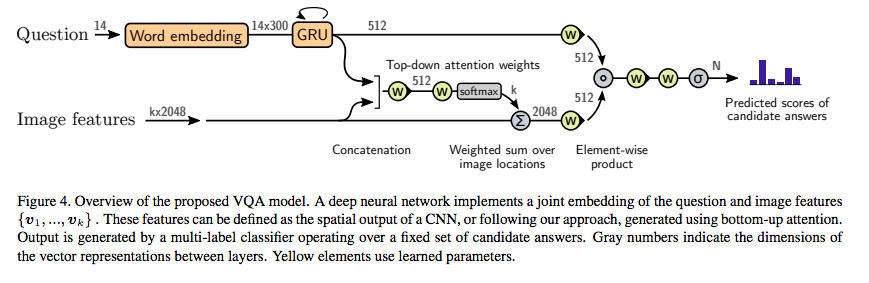
4. どうやって有効だと検証した?
データセット
- Visual Genome
- MSCOCO
- VQA v2.0
比較対象
Image Captioning
- SCST(SOTAだったモデル)
- ResNet(提案手法のbottom-up attentionをResNetに置換)
- up-down(bottom-up and top-down approach)
ResNetはvisual attentionにResNet101を用いて,最終層のconv layerの出力を10*10にリサイズ. 通常のvisual attentionと同様に,pixel-wiseのfeature vectorに対してattentionを貼る.
評価
- BLEU, METEOR, ROUGE-L, CIEDErは高いほど良い,
- SPICEは小さいほど良い.
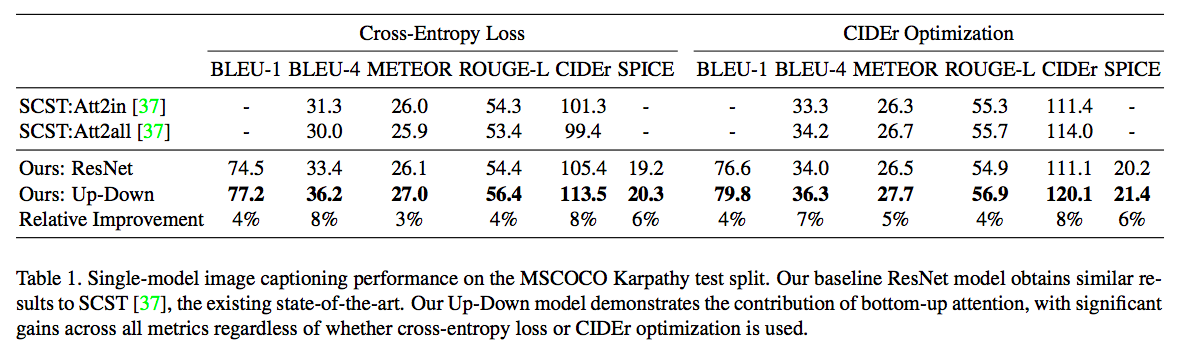
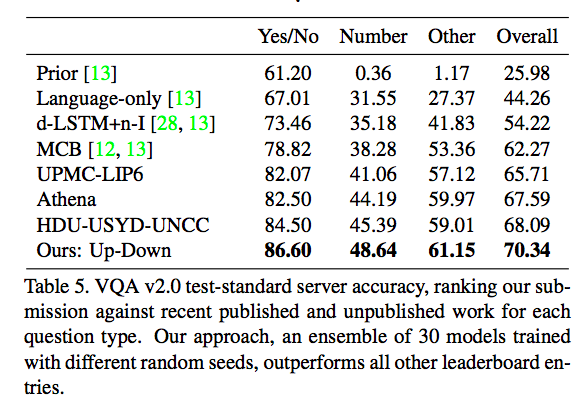
Image Captioningのタスクでは全ての評価指標において,現SOTAのモデルを上回った. VQAのタスクでは,2017 VQA challengeに投稿された全てのモデルを上回る正解率であった.
5. 議論はあるか?


6. 次に読むべき論文はあるか?
- 'Damien Teney, Peter Anderson, Xiaodong He, Anton van den Hengel', "Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge",'2017 VQA Challenge'
- 'S. Ren, K. He, R. Girshick, and J. Sun', 'Faster R-CNN: Towards real-time object detection with region proposal networks', 'NIPS 2015'
- 'V. Kazemi and A. Elqursh', 'Show, ask, attend, and answer: A strong baseline for visual question answering.'
論文情報・リンク
Articles connexes
- Thu 26 July 2018
- Rich Image Captioning in the Wild
- Mon 02 July 2018
- SemStyle: Learning to Generate Stylised Image Captions using Unaligned Text
- Mon 11 June 2018
- Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
- Thu 02 August 2018
- Stacked Attention Networks for Image Question Answering
- Tue 15 May 2018
- Video Question Answering via Hierarchical Spatio-Temporal Attention Networks