1. どんなもの?
画像に映る様々なvisual conceptsを含む表現豊かなキャプションを生成する研究。 近年のimage captioningに関する研究はend-to-endが主であるが、この論文ではいくつかのモジュールから構成されるcompositional modelである。 人手の評価を用いてcompositional modelにおいてSOTAを達成。

上記の画像の例では、物体研究を用いることでcelebritiesとlandmarksをキャプションの結果に反映させた例である。
2. 先行研究と比べてどこがすごいの?
近年のimage captioningに関する研究では主にend-to-endによるMSCOCO captioning datasetやfliker datasetのみを用いる傾向にある。 したがって、open-domainな画像に対して強健なモデルとは言い難い。 また、モデルの評価時にBleu, spice, Ciderなどの指標を用いるが、これらの指標は人手の評価との相関が低い。
この研究では、画像に描画されるvisual conceptsを生成されるキャプションに組み込むことによって表現豊かなcaptioningを行う。 End-to-Endモデルとの比較は行われていないものの、従来のcompositional modelよりキャプションの精度が良かった。
3. 技術や手法の"キモ"はどこにある?
様々なモジュールの組み合わせることによってimage captioningを行っている。
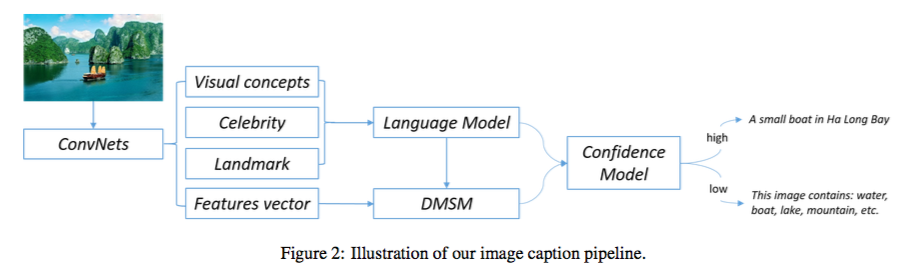
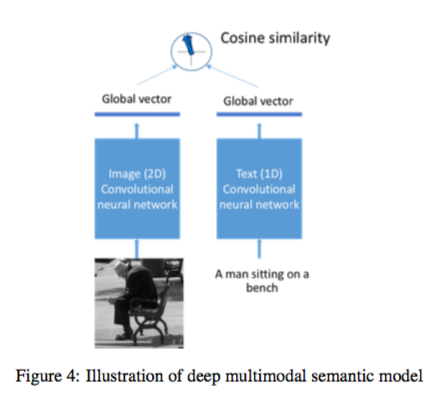
CNNベースの分類器を用いて物体の検出(Visual concepts, Celebrity, Landmark)を行い、maximum entropy language model(MELM)によりキャプションを生成する。 また、Deep multimodal similarity model(DMSM)により、input imageのCNNを適用した後の特徴量とMELMにより生成されたキャプションを同一の意味空間上に落とし込む。 DMSMにより、画像とキャプションのcosin距離を計算し、キャプションの信頼性のscoreとして用いる。 Confidence modelは単純なロジスティク回帰モデルである。 DMSMのscore, MELMのscore, caption lengthなどを特徴量として用いる。 confidenc modelの確率が高いキャプションはそのまま出力し、低い場合は "This image contains XXX, YYY, ZZZ"のよう物体検出の結果を出力する。
4. どうやって有効だと検証した?
データセット
- MSCOCO
- MIT Dataset
- images on imstagram sampled randomly
比較対象
- Fang et al(SOTAだったモデル)
- Basic(confidence model, 物体検出なし)
- Basic+Confi(物体検出なし)
- Full(提案手法)
評価
人手の評価を行った。
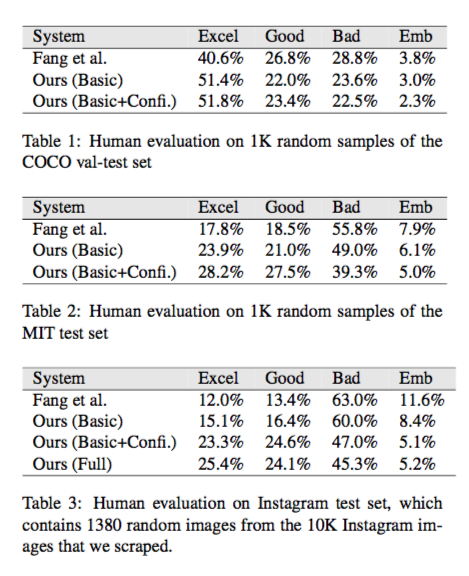
compositional modelの従来のSOTAであったモデルよりキャプションの精度が良かった。
5. 議論はあるか?
Bleuなどの評価指標を用いた実験を行っていないため、他のEnd-to-Endモデルとの比較ができない。 instagram上のopen-domainな画像に対してはExcellent及びGoodと判断されたキャプションが全体の50%であった。
Confidence scoreが低い時に物体検出の結果を出力するのはどうかと思った。 物体検出の結果を出力すれば、Goodの割合が必然的に増加するのではないかと考えられる。
