1. どんなもの?
image captioningに関する研究 既存の研究はpaired dataを用いてfactualなcaption(画像の状況を客観的に記述したもの)を生成する手法が主流であったが、 本研究ではスタイルを適用したcaption(romantic caption, humorous caption)を生成している。
以下の図にスタイルを適用したキャプションの例を示す。
- Fは特定スタイルを含まない客観的に画像を述べたキャプション
- Rは恋愛小説のスタイルを含むキャプション
- Hはユーモアのスタイルを含むキャプション

2. 先行研究と比べてどこがすごいの?
先行研究ではpaired dataによるfactualなcaption生成が主流であったが、 本研究ではMSCOCOなどのpaired dataと適用したいスタイルを含むunpairedなdata(文章集合)を用いることによって、 スタイルを適用したキャプションを生成することを可能にした。
3. 技術や手法の"キモ"はどこにある?
基本のモデルはEncoer側にCNN, Decoder側にRNNを用いたseq2seqだが、decoderのRNNにLSTM cellを3つに分解したFactored LSTMを使用。 Factored LSTM cellは従来のLSTM cellのパラメーターを分解(\(W_x = U_xS_xV_x\))したものである。 したがって、Factored LSTMのcellは以下のようになる。
\(i_t = sigmoid(U_{ix}S_{ix}V_{ix}x_t + W_{ih}h_{t-1})\)
\(f_t = sigmoid(U_{fx}S_{fx}V_{fx}x_t + W_{fh}h_{t-1})\)
\(o_t = sigmoid(U_{ox}S_{ox}V_{ox}x_t + W_{oh}h_{t-1})\)
\(\bar{c}_t = tanh(U_{cx}S_{cx}V_{cx}x_t + W_{ch}h_{t-1})\)
\(c_t = f_t \odot c{t-1} + i_t \odot \bar{c}t\)
\(c_t = o_t \odot c_t\)
t番目のステップのtokenに対してのみ、分解した全パラメータを用い、t-1番目の状態である\(h_t-1\)に対しては\(W_h\)を用いる。
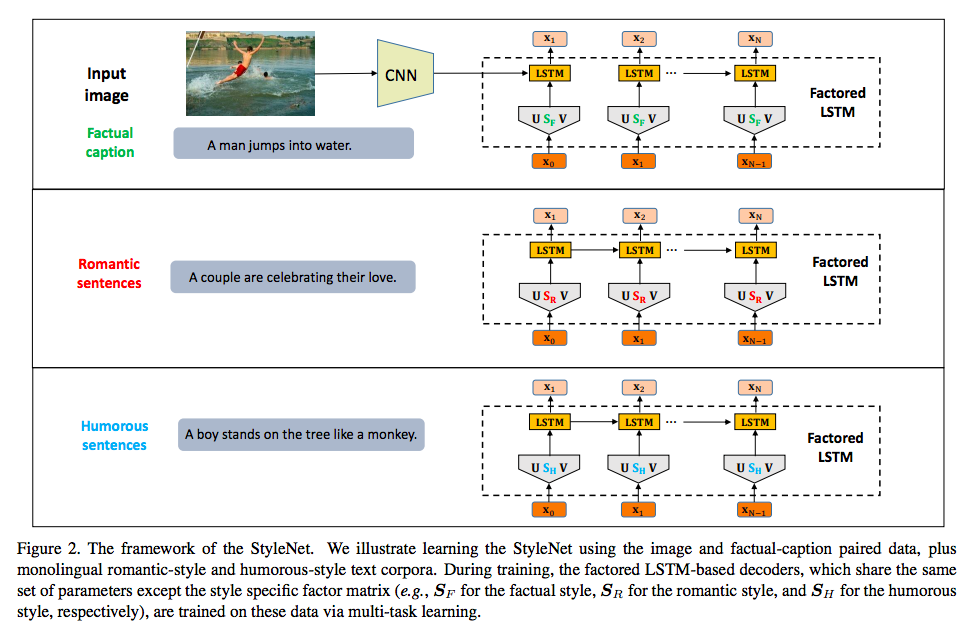
また、学習時にはFacturalなcaption生成用のDecoderとスタイルを適用したcaption生成用のDecoderを1 poech毎に切り替えたmulti task learningを行う。 Factored LSTMのパラメータSのみを入れ替えつつfacturel captionとstyled captionの生成を行うため、contextに関する情報がU, \(V\)に学習され、\(S\)にstyleが学習されると想定される。
4. どうやって有効だと検証した?
データセット
- FlickerStyle10K dataset 10kものFliker imagesとstylized captionsを含むデータセット
評価
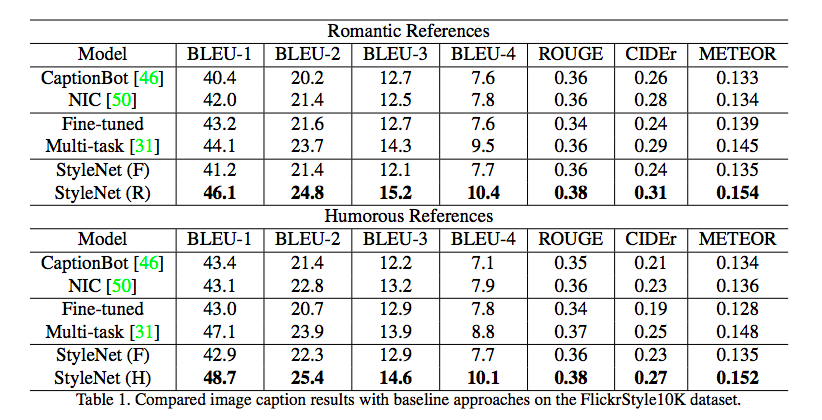
- 評価指標による評価
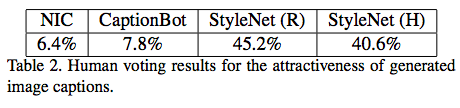
- 人手による評価
5. 議論はあるか?
Facored LSTMによってパラメータ\(S_x\)に対してのみスタイルを適用するメカニズムがいまいち謎。 全体的にお気持論文な傾向がある。。。 CNNベースでスタイルを適用したcaption生成が可能なら、RNNを用いて文章のStyle transferに応用できるのでは?